2024. 10. 3. 16:37ㆍBackend/Java
LogQueue를 구현하면서, 동기화 수단이 필요했는데 이때 synchornized를 사용하는 방법과 ReentrantLock을 사용하는 방법 중 어떤 것을 써야 할지 궁금해졌다.
둘의 차이는, 기본적으로 ReentrantLock을 쓰면 락을 명시적으로 제어 가능하면서, Condition의 대기 공간을 여러 개 만들 수 있다는 장점이 있었는데
이 외에는 성능 차이가 얼마나 나는지 궁금해졌다.
둘 다 내부적으로 spin 등을 이용하여 최적화가 잘 되어있는데, light-weight한 경우와 heavy-weight 한 경우에 대해 모두 다 성능 차이가 얼마나 있을지 비교해 보기로 했다.
LogQueue에 동기화 별 성능 차이 비교
LogBat 프로젝트에서 사용했던 LogQueue에 대해 동기화 수단을 ReentranLock과 synchronized 둘을 사용하여 성능 비교를 해봤다.
LogQueue 구현
@Component
public class ReentrantLogQueue<T> implements EventProducer<T>, EventConsumer<T> {
private final LinkedList<T> queue = new LinkedList<>();
private final long timeout;
private final int bulkSize;
private final ReentrantLock bulkLock = new ReentrantLock();
private final Condition bulkCondition = bulkLock.newCondition();
public ReentrantLogQueue(@Value("${jdbc.async.timeout}") Long timeout,
@Value("${jdbc.async.bulk-size}") Integer bulkSize) {
this.timeout = timeout;
this.bulkSize = bulkSize;
}
@Override
public List<T> consume() {
List<T> result = new ArrayList<>();
try {
bulkLock.lockInterruptibly();
// Case1: Full Flush
if (queue.size() >= bulkSize) {
for (int i = 0; i < bulkSize; i++) {
result.add(queue.poll());
}
return result;
}
// Else Case: Blocking
// Blocked while Queue is Not Empty
do {
bulkCondition.await(timeout, TimeUnit.MILLISECONDS);
} while (queue.isEmpty());
// Bulk Size 만큼 꺼내서 반환
for (int i = 0; i < bulkSize; i++) {
result.add(queue.poll());
if (queue.isEmpty()) {
break;
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
bulkLock.unlock();
}
return result;
}
@Override
public void produce(List<T> data) {
bulkLock.lock();
try {
queue.addAll(data);
if (queue.size() >= bulkSize) {
bulkCondition.signal();
}
} finally {
bulkLock.unlock();
}
}
* Synchronized 에서는 lock을 거는 부분과 wait 부분만 synchronized를 쓰는 코드로 바꾸고, 나머지 로직은 동일하다.
테스트 코드
Thread producer = new Thread(() -> {
for (int i = 0; i < 1_000_000; ++i) {
List<String> produceList = new ArrayList<>();
for(int c = 0;c<100;++c) {
produceList.add("produce : " + i);
}
logQueue.produce(produceList);
}
});
Thread consumer = new Thread(() -> {
int totalCount = 0;
while (totalCount < 100_000_000) {
List<String> consume = logQueue.consume();
totalCount += consume.size();
System.out.println("totalCount = " + totalCount);
}
System.out.println("Done");
});
consumer.start();
producer.start();
consumer.join();
}
참고로 synchronized에서 사용하는 모니터 락에는 편향 락, light-weight lock, heavy-weight lock이 있었는데, 이 중에 편향 락은 JDK 15부터 편향 락이 사라졌다.
따라서, synchronized을 사용할 때 매번 객체 헤더에 락을 획득하기 위해 spin 하는 light-weight가 기본적으로 동작한다.
경쟁이 거의 없는 경우, Monitor와 ReentrantLock간 비교
ReentrantLock을 사용할 때도 Lock경쟁이 심하지 않아

Thread의 wait이 전혀 발생하지 않았다.
이는 AQS의 CLH 큐에 들어가서 park하지 않고, 들어가기 직전의 스핀 내에서 lock을 모두 획득한 것을 확인할 수 있다.
Synchronized를 사용하는 상황을 고려해보더라도
경쟁이 심하지 않다고 판단하여, Monitor Blocked가 전혀 발생하지 않은 것을 확인할 수 있다. Monitor Blocked는 Heavy-weight lock에서만 발생하는 현상으로, Mark Word를 cas 하는 spin 내에서 락을 모두 획득한 것으로 이해할 수 있다.
lock을 얻는 성능은?
Producer도 싱글 스레드이고, Consumer도 싱글 스레드이기 때문에 사실상 lock을 얻는 데에는 실제 Thread가 대기 상태로 전환되지 않는 것을 확인할 수 있었다.
이는 Monitor에서 light-weight Lock이 사용됐거나, Heavy-weight에서 spin이내에 다 Lock을 획득한 것으로 볼 수 있다.
경합이 거의 없는 환경에서는 synchronized와 ReentrantLock의 성능 차이가 거의 없었다.
경쟁이 심한 환경에서는?
synchronized
의도적으로 경쟁이 심한 환경을 만들어주어 테스트를 해봤다.
경쟁이 심해지자 Monitor Inflation이 발생하여 heavy-weight lock이 사용되게 되고, Java Monitor Blocked가 발생했다.
노란색으로 표시된 부분이 Monitor Blocked 된 부분을 나타낸다.
Monitor Inflation이란
light-weight lock으로 동작하던 스레드가 경합이 심해져 실제 스레드를 대기시키는 무거운 락을 뜻하는 heavy-weight lock으로 전환되는 것을 의미한다.
모니터가 기본적으로는 light-weight lock을 기준으로 동작하는데, 이 때는 객체 헤더의 mark word를 cas를 통해 변경하며 spin 하는 방식으로 동작한다. (편향 락은 JDK 15부터 제거됐다!!)
이렇게 spin 하면서 cas 실패가 누적되면 JVM에서는 경합 상황으로 판단하여 heavy-weight lock으로 전환하는 Monitor Inflation을 진행한다.
https://www.usenix.org/legacy/event/jvm01/full_papers/dice/dice.pdf
Monitor Deflation Thread란?
heavy-weight lock의 모니터가 필요하지 않으면 다시 가벼운 상태로 되돌아가는 작업을 수행하는 스레드를 의미한다.
ReentrantLock
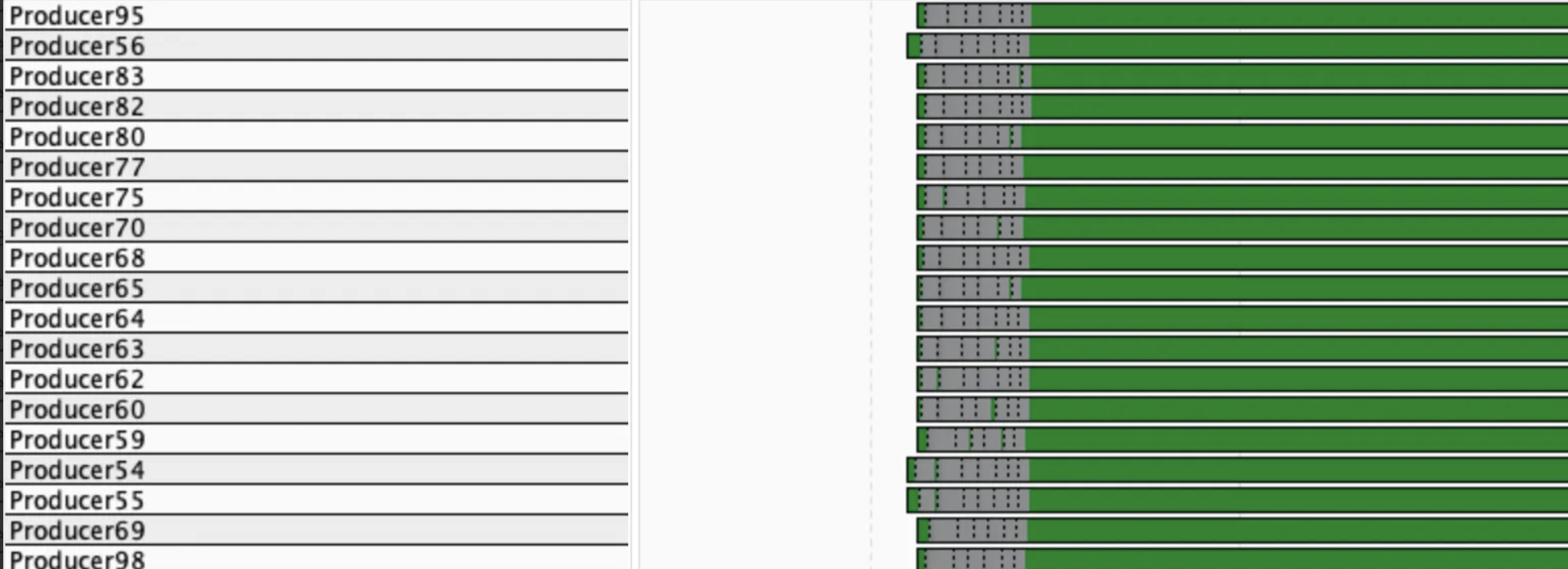
ReentrantLock의 경우 대기 시 Blocked상태가 아니라 Park를 통해 Waiting 하기 때문에 Monitor Blocked가 아니라 Park이 발생한 것을 확인할 수 있다.
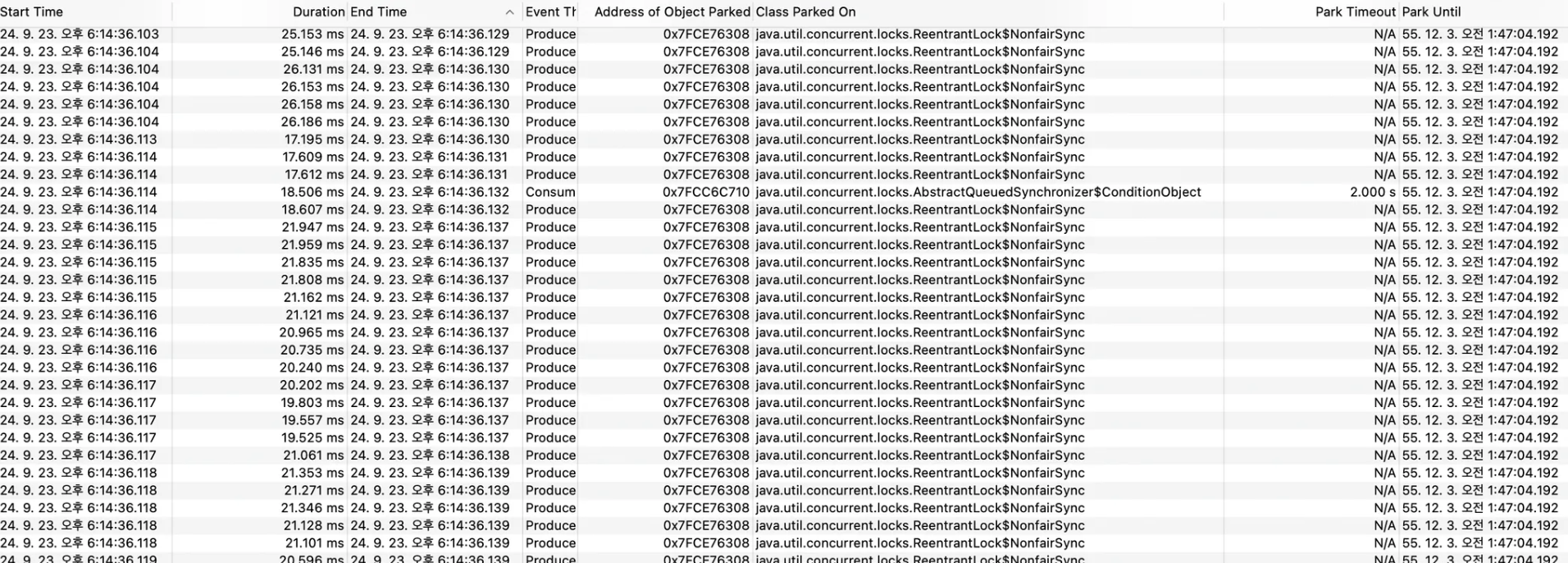
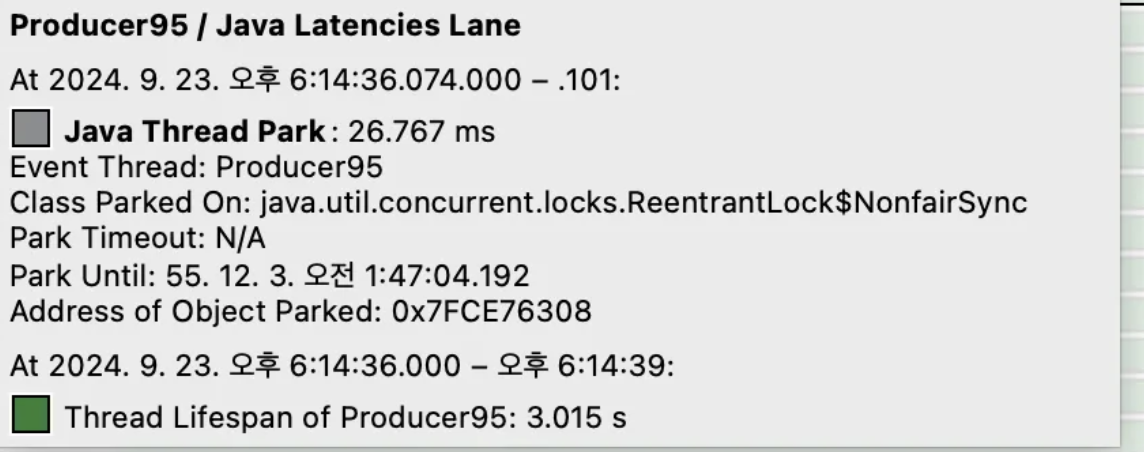
성능의 경우에는 경쟁이 심할 때에도 경쟁이 거의 없을 때와 비슷하게


거의 같은 성능을 제공한다.
사실상 암시적 락인 synchronized와 명시적 락인 ReentrantLock의 성능차이는 거의 없다고 봐도 무방할 것 같다.
왜 둘의 성능이 거의 비슷했을까?
처음에는 ‘synchronized는 무조건 느릴 것이다’라는 편견을 가지고 있었다. 이 궁금증을 해결하기 위해 Monitor Lock이 어떻게 작동하는지 살펴보기 위해 코드를 찾아봤다.
Monitor Lock 작동 방법 알아보기 (heavy-weight Lock)
Monitor Lock의 동작과 관련된 부분은 Java코드로 구현돼있지 않고, JVM에서 동작하는 ObjectMonitor.cpp에 C++ Native Code로 구현돼 있었다. (heavy-weight lock의 경우, light-weight lock은 다른 cpp파일임)
ObjectMonitor.cpp
락을 걸 때는 enter 메서드를 사용한다.
ObjectMonitor::enter
bool ObjectMonitor::enter(JavaThread* current) {
assert(current == JavaThread::current(), "must be");
if (spin_enter(current)) {
return true;
}
assert(owner_raw() != current, "invariant");
assert(_succ != current, "invariant");
assert(!SafepointSynchronize::is_at_safepoint(), "invariant");
assert(current->thread_state() != _thread_blocked, "invariant");
// Keep is_being_async_deflated stable across the rest of enter
ObjectMonitorContentionMark contention_mark(this);
// Check for deflation.
if (enter_is_async_deflating()) {
return false;
}
// At this point this ObjectMonitor cannot be deflated, finish contended enter
enter_with_contention_mark(current, contention_mark);
return true;
}
light-weight에서 inflate 돼서 호출된 ObjectMonitor::enter에서도 내부적으로 spin을 통해 락을 획득하려 한다.
ObjectMonitor에서는 _owner라는 필드에 cas를 통해 owner를 설정하여 lock을 획득한다.
objectMonitor.inlie.hpp
// Try to set _owner field to new_value if the current value matches
// old_value. Otherwise, does not change the _owner field. Returns
// the prior value of the _owner field.
inline void* ObjectMonitor::try_set_owner_from(void* old_value, void* new_value) {
void* prev = Atomic::cmpxchg(&_owner, old_value, new_value);
if (prev == old_value) {
log_trace(monitorinflation, owner)("try_set_owner_from(): mid="
INTPTR_FORMAT ", prev=" INTPTR_FORMAT
", new=" INTPTR_FORMAT, p2i(this),
p2i(prev), p2i(new_value));
}
return prev;
}
Atomic::cmpxchg라는 cas연산을 통해 new_value로 설정하려고 한다.
-> 따라서, heavy-weight lock에서 커널의 lock (ex, mutex)을 이용한다는 것은 잘못되었다.
spin으로 락 획득 시도 spin_enter
ObjectMonitor::spin_enter
bool ObjectMonitor::spin_enter(JavaThread* current) {
.
.
.
if (TrySpin(current)) {
assert(owner_raw() == current, "must be current: owner=" INTPTR_FORMAT, p2i(owner_raw()));
assert(_recursions == 0, "must be 0: recursions=" INTX_FORMAT, _recursions);
assert_mark_word_consistency();
return true;
}
return false;
}
spin_enter에서 TrySpin이라는 메서드를 호출하여 락을 획득하려 시도한다.
ObjectMonitor::TrySpin
bool ObjectMonitor::TrySpin(JavaThread* current) {
int knob_fixed_spin = Knob_FixedSpin; // 0 (don't spin: default), 2000 good test
if (knob_fixed_spin > 0) {
return short_fixed_spin(current, knob_fixed_spin, false);
}
int knob_pre_spin = Knob_PreSpin; // 10 (default), 100, 1000 or 2000
if (short_fixed_spin(current, knob_pre_spin, true)) {
return true;
}
int ctr = _SpinDuration;
if (ctr <= 0) return false;
if (_succ == nullptr) {
_succ = current;
}
Thread* prv = nullptr;
while (--ctr >= 0) {
if ((ctr & 0xFF) == 0) {
if (SafepointMechanism::local_poll_armed(current)) {
break;
}
SpinPause();
}
JavaThread* ox = static_cast<JavaThread*>(owner_raw());
if (ox == nullptr) {
ox = static_cast<JavaThread*>(try_set_owner_from(nullptr, current));
if (ox == nullptr) {
// The CAS succeeded -- this thread acquired ownership
// Take care of some bookkeeping to exit spin state.
if (_succ == current) {
_succ = nullptr;
}
_SpinDuration = adjust_up(_SpinDuration);
return true;
}
break;
}
// Did lock ownership change hands ?
if (ox != prv && prv != nullptr) {
break;
}
prv = ox;
if (_succ == nullptr) {
_succ = current;
}
}
// Spin failed with prejudice -- reduce _SpinDuration.
if (ctr < 0) {
_SpinDuration = adjust_down(_SpinDuration);
}
if (_succ == current) {
_succ = nullptr;
OrderAccess::fence();
if (TryLock(current) == TryLockResult::Success) {
return true;
}
}
return false;
}
코드를 간단하게 설명하면, spin 하여 락을 획득하려는 코드이다.
_SpinDuration이라는 값을 통해 적응형으로 spin횟수를 결정한다.
최근에 spin으로 락을 획득한 경우, 후속 요청도 spin으로 락을 획득할 확률이 높다고 판단하여 spin횟수를 증가한다.
또는, spin으로 락을 획득하지 못한 경우, spin으로 락을 획득할 수 없다고 판단하여 불필요한 spin을 줄인다.
스핀을 시도한 후, enter_with_contention_mark
ObjectMonitor::enter_with_contention_mark
void ObjectMonitor::enter_with_contention_mark(JavaThread *current, ObjectMonitorContentionMark &cm) {
.
.
.
{ // 스레드가 ObjectMonitor에 들어오면 상태를 blocked로 변경한다.
JavaThreadBlockedOnMonitorEnterState jtbmes(current, this);
assert(current->current_pending_monitor() == nullptr, "invariant");
current->set_current_pending_monitor(this);
DTRACE_MONITOR_PROBE(contended__enter, this, object(), current);
if (JvmtiExport::should_post_monitor_contended_enter()) {
JvmtiExport::post_monitor_contended_enter(current, this);
}
OSThreadContendState osts(current->osthread());
for (;;) {
ExitOnSuspend eos(this);
{
ThreadBlockInVMPreprocess<ExitOnSuspend> tbivs(current, eos, true);
EnterI(current); // 핵심 메서드
current->set_current_pending_monitor(nullptr);
}
if (!eos.exited()) {
assert(owner_raw() == current, "invariant");
break;
}
}
}
.
.
.
}
여기에서 EnterI(current)가 스레드가 실제로 모니터에 진입하게 하는 핵심 메서드이다.
ObjectMonitor::EnterI
void ObjectMonitor::EnterI(JavaThread* current) {
assert(current->thread_state() == _thread_blocked, "invariant");
// TryLock을 사용하여 락을 시도
if (TryLock(current) == TryLockResult::Success) {
assert(_succ != current, "invariant");
assert(owner_raw() == current, "invariant");
return;
}
// 스핀락을 시도하지만 실패하면 현재 스레드를 cxq에 추가하고 대기
if (TrySpin(current)) {
assert(owner_raw() == current, "invariant");
assert(_succ != current, "invariant");
return;
}
// 현재 스레드를 _cxq에 추가
ObjectWaiter node(current);
current->_ParkEvent->reset();
node._prev = (ObjectWaiter*) 0xBAD;
node.TState = ObjectWaiter::TS_CXQ;
// cxq에 현재 스레드를 추가하는 루프
for (;;) {
node._next = _cxq;
if (Atomic::cmpxchg(&_cxq, _cxq, &node) == _cxq) break;
if (TryLock(current) == TryLockResult::Success) {
assert(_succ != current, "invariant");
assert(owner_raw() == current, "invariant");
return;
}
}
// 스레드를 park하여 대기
for (;;) {
if (TryLock(current) == TryLockResult::Success) {
break;
}
assert(owner_raw() != current, "invariant");
// park self
current->_ParkEvent->park();
if (TryLock(current) == TryLockResult::Success) {
break;
}
}
.
.
.
}
cxq라는 것이 contention Queue로, ReentrantLock의 AbstractQueuedSynchronizer의 CLH 대기 큐와 같은 대기 목록을 뜻한다.
tryLock을 한 뒤, TrySpin을 하여 락을 획득 시도하여 락을 최대한 획득하려 시도하고,
실패하면 cxq에 추가한 이후, ParkEvent → park()를 호출한다.
이때 ParkEvent → park()는 Os별로 다른 코드가 실행되는데, linux를 기준으로는 os_posix.cppd의 PlatformEvent::park()가 실행된다.
스레드를 대기 상태로 전환시키기 위한 부분, PlatformEvent::park()
os_posix.cpp
void PlatformEvent::park() {
.
.
.
int status = pthread_mutex_lock(_mutex);
assert_status(status == 0, status, "mutex_lock");
guarantee(_nParked == 0, "invariant");
++_nParked;
while (_event < 0) {
// OS-level "spurious wakeups" are ignored
status = pthread_cond_wait(_cond, _mutex);
assert_status(status == 0 MACOS_ONLY(|| status == ETIMEDOUT),
status, "cond_wait");
}
--_nParked;
_event = 0;
status = pthread_mutex_unlock(_mutex);
assert_status(status == 0, status, "mutex_unlock");
// Paranoia to ensure our locked and lock-free paths interact
// correctly with each other.
OrderAccess::fence();
.
.
}
실제로 스레드를 대기시키는 부분은 이 PlatformEvent::park()에서 수행되는데
내부적으로 pthread_mutex_lock을 얻은 뒤, pthread_cond_wait을 통해 Thread를 대기 상태로 변경시킨다.
여기서 pthread_mutex_lock을 호출하는 것은, 스레드를 대기 상태로 전환시키기 위한 것일 뿐이지, 커널의 lock을 쓰는 것은 아니다.
(위에서 ObejctMonitor::try_set_owner_from부분에서 설명해 두었다.)
다시 정리하면 Heavy-weight Lock이라고 커널의 lock을 쓰는 것은 아니다.
그렇다면 왜 posix에서 스레드를 대기 상태로 변경하기 위해서는 mutex_lock을 얻어야만 하게 설계했을까?
사실 이거는, Condition의 설계 목적과 상관있는 것 같다.
wait은 Condition의 wait을 설계할 때에는 상태관리의 원자성을 위해 lock을 얻은 이후 wait을 하게 설계했는데,
스레드를 대기시키는 기능만 뽑아내서 쓰려다 보니 이런 현상이 필요했던 것 같다.
LockSupport.park()는 어떻게 wait상태로 변경할까?
ReentrantLock 내에서 사용하는 LockSupport.park()는 어떤 메커니즘으로 대기 상태로 변경시키는 걸 지 궁금해서 찾아봤다.
public static void park() {
if (Thread.currentThread().isVirtual()) {
VirtualThreads.park();
} else {
U.park(false, 0L);
}
}
LockSupport.park()는 내부적으로 Unsafe의 park메서드를 호출한다.
public final class Unsafe {
public native void park(boolean isAbsolute, long time);
}
Unsafe의 park 메서드는 native 메서드로 구현돼 있다.
Unsafe.park
unsafe.cpp
UNSAFE_ENTRY(void, Unsafe_Park(JNIEnv *env, jobject unsafe, jboolean isAbsolute, jlong time)) {
HOTSPOT_THREAD_PARK_BEGIN((uintptr_t) thread->parker(), (int) isAbsolute, time);
EventThreadPark event;
JavaThreadParkedState jtps(thread, time != 0);
thread->parker()->park(isAbsolute != 0, time);
if (event.should_commit()) {
const oop obj = thread->current_park_blocker();
if (time == 0) {
post_thread_park_event(&event, obj, min_jlong, min_jlong);
} else {
if (isAbsolute != 0) {
post_thread_park_event(&event, obj, min_jlong, time);
} else {
post_thread_park_event(&event, obj, time, min_jlong);
}
}
}
HOTSPOT_THREAD_PARK_END((uintptr_t) thread->parker());
} UNSAFE_END
Unsafe의 park에서는 parekr()→park를 호출하는데 이것 또한 아까 살펴봤던 os_posix.cpp의 메서드를 실행한다.
하지만 Monitor에서는 ParkEvent→park()를 사용했고, Unsafe에서는 Parker→park()를 사용한다.
void Parker::park(bool isAbsolute, jlong time) {
// Optional fast-path check:
// Return immediately if a permit is available.
// We depend on Atomic::xchg() having full barrier semantics
// since we are doing a lock-free update to _counter.
if (Atomic::xchg(&_counter, 0) > 0) return;
JavaThread *jt = JavaThread::current();
// Optional optimization -- avoid state transitions if there's
// an interrupt pending.
if (jt->is_interrupted(false)) {
return;
}
// Next, demultiplex/decode time arguments
struct timespec absTime;
if (time < 0 || (isAbsolute && time == 0)) { // don't wait at all
return;
}
if (time > 0) {
to_abstime(&absTime, time, isAbsolute, false);
}
// Enter safepoint region
// Beware of deadlocks such as 6317397.
// The per-thread Parker:: mutex is a classic leaf-lock.
// In particular a thread must never block on the Threads_lock while
// holding the Parker:: mutex. If safepoints are pending both the
// the ThreadBlockInVM() CTOR and DTOR may grab Threads_lock.
ThreadBlockInVM tbivm(jt);
// Can't access interrupt state now that we are _thread_blocked. If we've
// been interrupted since we checked above then _counter will be > 0.
// Don't wait if cannot get lock since interference arises from
// unparking.
if (pthread_mutex_trylock(_mutex) != 0) {
return;
}
int status;
if (_counter > 0) { // no wait needed
_counter = 0;
status = pthread_mutex_unlock(_mutex);
assert_status(status == 0, status, "invariant");
// Paranoia to ensure our locked and lock-free paths interact
// correctly with each other and Java-level accesses.
OrderAccess::fence();
return;
}
OSThreadWaitState osts(jt->osthread(), false /* not Object.wait() */);
assert(_cur_index == -1, "invariant");
if (time == 0) {
_cur_index = REL_INDEX; // arbitrary choice when not timed
status = pthread_cond_wait(&_cond[_cur_index], _mutex);
assert_status(status == 0 MACOS_ONLY(|| status == ETIMEDOUT),
status, "cond_wait");
}
else {
_cur_index = isAbsolute ? ABS_INDEX : REL_INDEX;
status = pthread_cond_timedwait(&_cond[_cur_index], _mutex, &absTime);
assert_status(status == 0 || status == ETIMEDOUT,
status, "cond_timedwait");
}
_cur_index = -1;
_counter = 0;
status = pthread_mutex_unlock(_mutex);
assert_status(status == 0, status, "invariant");
// Paranoia to ensure our locked and lock-free paths interact
// correctly with each other and Java-level accesses.
OrderAccess::fence();
}
Parker는 단순 wait 이외에 timed waiting을 지원한다.
하지만, 스레드를 대기 상태로 바꾸는 방법은 기존 ParkEvent→park와 같이 mutex lock을 획득한 이후 wait 메서드를 호출하는 방법으로 동일하다.
따라서 모니터 락에서 대기하든, ReentrantLock에서 대기하든 커널 스레드의 상태 변화는 같고,
JVM 내에서 Blocked나 Waiting으로 다르게 표기하는 것이다.
결론
ReentrantLock을 쓰는 것과, Synchronized를 쓸 때의 성능 차이는 거의 미미하다고 봐도 무방하다.
굳이 차이를 찾자면, ReentrantLock의 대기 공간은 순수 Java로 구현돼 있어 JVM 힙 메모리 공간을 쓸 것이고,
Synchronized의 Monitor는 native 메서드 내에서 동작하기 때문에 JVM 힙 메모리를 사용하지 않고, 네이티브 메서드에 필요한 외부 메모리 공간을 쓰게 될 것이다.
'Backend > Java' 카테고리의 다른 글
| 제네릭 배열은 왜 안 될까?, TypeReference는 어떻게 런타임에 제네릭 타입 정보를 보존할까? (1) | 2024.09.26 |
|---|---|
| Condition이 동작하는 원리 (ReentrantLock + AbstractQueuedSynchronizer) (2) | 2024.09.22 |
| ReentrantLock이 동작하는 원리 (AbstractQueuedSynchronizer) (1) | 2024.09.17 |